
目录
LZ77压缩与原理
完整的压缩过程
解压过程
LZ4压缩算法
总结
如果一句话概括LZ4:LZ4就是一个用16k大小哈希表储存字典并简化检索的LZ77。
那么LZ77又是什么呢?
LZ77压缩与原理
LZ77是一个应用了字典来进行压缩的算法。通俗来说,就是让程序观察(看字典)当前看到的数据是否和之前有重复, 如果有的话,我们就保存两个重复字段的距离(offset)和重复的长度,以替代重复的字段而以此来压缩数据。
参考https://msdn.microsoft.com/en-us/library/ee916854.aspx
对于一串字母 A A B C B B A B C, 在读到第二个A的时候, 程序就会保存 (1,1) (距离上一个重复1位,长度为1),同理,在读到第二个B的时候,程序就会保存(2,1)(距离2,长度1)。
但是假如字符串更长些,并且程序把数据一直都记录进字典,那检索重复字段的工作就会变得异常耗时,因为最坏情况下程序每读到一个新的字母就会历遍整个字典。 LZ77使用了滑动窗口的方法来解决这个问题。
与TCP使用滑动窗口的出发点相似,滑动窗口可以缩小缓存区来避免同时处理过多缓存数据。在LZ77中,字典不是一直增加的,而是在超过字典规定的最大大小时舍弃最早加入字典的字符,以此来保证字典的大小始终维持在规定的最大大小。
假设字典长度为3
| dictionary |
| A | A B C B B A B C
输出(0,0,A)
| A A | B C B B A B C
输出(1,1)
| A A B | C B B A B C
输出(0,0,B)
A | A B C | B B A B C
输出(0,0,C)
A A | B C B | B A B C
输出(2,1)
滑动窗口的另外一部分则是待搜索缓存(look ahead buffer没有正规翻译)。 待搜索缓存就是离字典最近的还未经压缩的一部分长度。 LZ77算法会在这部分字符中匹配出与字典相同的最长字符串。
假设字典长度为5,待搜索缓存大小为3
| dictionary | look ahead buffer |
A | A B C B B | A B C |
输出(5,3)
匹配出的最长字符串为ABC
完整的压缩过程
假设字典长度为5,待搜索缓存大小为3
| dictionary | look ahead buffer |
| A A B | C B B A B C
输出(0,0,A)
| A | A B C | B B A B C
输出(1,1)
| A A | B C B | B A B C
输出(0,0,B)
| A A B | C B B | A B C
输出(0,0,C)
| A A B C | B B A | B C
输出(2,1)
| A A B C B | B A B | C
输出(1,1)
A | A B C B B | A B C |
输出(5,3)
A A B C | B B A B C | 。。。 |
在压缩程序的输出文件中无需保存字典,因为解压程序会通过输出的匹配单元来还原字典。
解压过程
LZ77算法的一大优势便是它的解压非常快捷。
第一个匹配单元是 (0,0,A),则输出A。
第二个匹配单元是 (1,1),则复制输出字符串中前一位,复制长度为1,则输出A。
。。。
最后一个匹配单元是 (5,3),则复制输出字符串中往回看5位,复制长度为3,则输出A,B,C.
在LZ77算法进行压缩时,耗时最多的部分是在字典中找到待搜索缓存中最长的匹配字符。若是字典和待搜索缓存过短,则能找到匹配的几率就会很小。所以LZ4对LZ77针对匹配算法进行了改动。
首先,LZ4算法的字典是一张哈希表。 字典的key是一个4字节的字符串,每个key只对应一个槽,槽里的value是这个字符串的位置。
LZ4没有待搜索缓存, 而是每次从输入文件读入四个字节, 然后在哈希表中查找这字符串对应的槽,下文称这个字符串为现在字符串。
如果已经到最后12个字符时直接把这些字符放入输出文件。
如果槽中没有赋值,那就说明这四个字节第一次出现, 将这四个字节和位置加入哈希表, 然后继续搜索。
如果槽中有赋值,那就说明我们找到了一个匹配值。
如果槽中的值加滑动窗口的大小<现在字符的位置,那就说明匹配项位置超出了这个块的大小,那程序将哈希槽中的值更新成现在字符串的位置。
LZ4会检查一下有没有发生过hash冲突。如果槽中值所在位置的4字节与现在字符串的不相同,那一定是发生了hash冲突。作者自己编的xxhash也是以高效著称,但还是不可避免的会有冲突。遇到冲突, 程序也将哈希槽中的值更新成现在字符串的位置
最后我们能确认这个匹配项是有效的,程序会继续看匹配字符串后续的字符是不是也相同。最后复制从上一个有效匹配项结束到本次有效匹配项开始前的所有字符到压缩文件,并加上本次有效匹配项的匹配序列。
LZ4压缩算法
Collet 称LZ4输出的匹配单元为匹配序列(sequence),他们组成了LZ4的压缩文件。具体如下图:
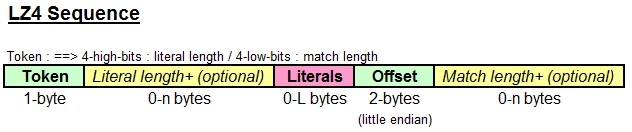
令牌(token)长为1字节,其中前4个字为字面长度(literal length),而其后4个字为匹配长度(match length)。前文中讲到会将上一个有效匹配项结束到本次有效匹配项开始前的所有字符复制到压缩文件,这些未经压缩的文件就是字面(literal),而他们的长度就是字面长度。
字面之后是偏差。和LZ77中偏差和匹配长度一样,偏差指的是现在字符串离它匹配项的长度,而匹配长度指的是现在字符串与字典中相同字符串的匹配长度。在解压是需要通过它来寻找需要复制的字符串和要复制的长度。偏差的大小是固定的。
图中literal length+和match length+ 是如果令牌中的字面或者匹配长度的4个字不够用了就在相应位置继续增加。4个字能表示0-15,再多的话就在增加一个字节,也就是大小加上255,直到字节中不满255。在匹配长度中,0代表4个字节。
最后12个字节在字面之后就结束了,因为它是直接被复制过去的。
我们来看下代码(python 比较抽象 )
)
def find_match(table, val, src_buf, src_ptr):
#find if there is a match in the hash table 从哈希表里看现在字符串是否有赋值
pos = table.get_position(val)
#get the value of table[] at index hashed val
if pos is not None and val == read_le_uint32(src_buf, pos):
# see if val == the value of src buf at index pos
if src_ptr - pos > MAX_OFFSET: # if the found match is too far away
return None
else:
return pos
else:
return None
def count_match(buf, front_idx, back_idx, max_idx):
#在确认匹配项有效之后,继续看匹配字符串后续的字符是不是也相同
cnt = 0
while back_idx <= max_idx:
#until back goes to max
if buf[front_idx] == buf[back_idx]:
#check if match found in buf
cnt += 1
else:
break
front_idx += 1
back_idx += 1
#since it is very likely that two sentences are repeated
return cnt
#dest_buffer, dst_ptr,memoryview(src_buffer),[literal_head:src_ptr],(src_ptr - match_pos, length)
def copy_sequence(dst_buf, dst_head, literal, match):
#literal is uncompressed, strait put in dest file将seqence写入输出文件
lit_len = len(literal)
dst_ptr = dst_head
# write literal length写入令牌(字面长度和匹配长度)
token = memoryview(dst_buf)[dst_ptr:dst_ptr + 1]
#token is a list of two pointers to match len and literal length
dst_ptr += 1
if lit_len >= 15:
#如果字面长度不够写
token[0] = (15 << 4)
remain_len = lit_len - 15
while remain_len >= 255:
#until lit_len reach a num smaller than 255(a byte) store the literal length
dst_buf [dst_ptr] = 255
dst_ptr += 1
remain_len -= 255
dst_buf[dst_ptr] = remain_len
dst_ptr += 1
else:
token[0] = (lit_len << 4)#moving space ffor match len
# write literal写入字面
dst_buf[dst_ptr: dst_ptr + lit_len] = literal
dst_ptr += lit_len
offset, match_len = match
if match_len > 0:
# write match offset
write_le_uint16(dst_buf, dst_ptr, offset)
dst_ptr += 2
# write match length如果匹配长度不够写
match_len -= MIN_MATCH
if match_len >= 15:
token[0] = token[0] | 15
match_len -= 15
while match_len >= 255:
dst_buf[dst_ptr] = 255
dst_ptr += 1
match_len -= 255
dst_buf[dst_ptr] = match_len
dst_ptr += 1
else:
token[0] = token[0] | match_len
return dst_ptr - dst_head
def lz4_compress_sequences(dest_buffer, src_buffer):
'''
Scan src_buffer, split it into sequences, store sequences to dest_buffer.
A sequence is a pair of literal and match
'''
src_len = len(src_buffer)
if src_len > MAX_BLOCK_INPUT_SIZE:
return 0
pos_table = PositionTable()
#creates hash Table 创造哈希表
src_ptr = 0 # the front of match指针表示现在字符串的位置
literal_head = 0 # store the literal head postition is the
dst_ptr = 0 # number of bytes writen to dest buffer
MAX_INDEX = src_len - MFLIMIT # remained buffer less than MFLIMIT will not be compressed
while src_ptr < MAX_INDEX:
#loop until 12 remaining left直到最后12位
current_value = read_le_uint32(src_buffer, src_ptr)
#reads 4 bytes读4字节
match_pos = find_match(pos_table, current_value, src_buffer, src_ptr)
#check if there exists a found position previously (a match) in the hash table 查询哈希表
if match_pos is not None:
length = count_match(src_buffer, match_pos, src_ptr, MAX_INDEX)
#see how long the match is 看看总共匹配有多长
if length < MIN_MATCH: # because of MAX_INDEX
break #I think never reached as each match is 4 byte
dst_ptr += copy_sequence(dest_buffer,
dst_ptr,
memoryview(src_buffer)[
literal_head:src_ptr],
(src_ptr - match_pos, length))
#将字面和匹配写入压缩文件
src_ptr += length
#skipping over the matched word
literal_head = src_ptr
else:
pos_table.set_position(current_value, src_ptr)
#没有匹配就把现在字符串的位置放进哈希表,
src_ptr += 1
#if the 4 byte value not found in hash table, put it in and see if sliding by 1 matches
# last literal最后的匹配项
dst_ptr += copy_sequence(dest_buffer, dst_ptr,
memoryview(src_buffer)[literal_head:src_len], (0, 0))
return dst_ptr
总结
说了这么多,还是没有总结一下为什么LZ4这么快。 我们首先来对比一下LZ77和LZ4对字典的检索。原生LZ77对字典的检索方式是在待搜索缓存区和字典中寻找最大匹配项。 这是一道在两个字符串中找最大相同字串的问题。 如果我们不使用动态规划,那最坏情况下就要考虑一个字符串的所有子串,然后还要在另一个字符串中进行匹配。 这样算下来,就需要O(m^2×n).如果使用动态规划,那我们则会使用一个表来保存动态的最长匹配项,而这样也只能让我们在O(m*n)的情况下完成匹配。 而且,这只是对一对搜索缓存区和字典来说。在最坏情况下, 如果没有任何匹配项,那LZ77就要算(整个文件的长度-待搜索缓存区长度)那么多道这样的匹配运算题。 而LZ4其实运用了一个更大层面上的动态规划:它将4字节与其位置保存在一个哈希表中,然后每次匹配新的4字节数据只需看哈希表中的值是不是有效。而找到有效匹配值之后看两组匹配值的后续数据时候也匹配则可以则可以找到它的最长匹配。由于LZ4的哈希表的每个key只对应1个槽,所以查找和增改哈希表的工作只需要O(1).如果在匹配后续找到了更多匹配,则需要更多组比较,但是在总时间里这些比较会代替更多的查哈希表的时间,所以LZ4算法的总时间只有O(n).不得不赞叹Collet的算法的美感啊!为了让算法的速度更上一层楼,Collet 设置默认的哈希表大小为16k,推荐不要超过32k,这样就能把它放进几乎所有cpu(intel)的一级缓存里。大家都知道cpu一级缓存的速度和内存比是天差地别的,所以LZ4的飞快速度也不足为奇,更何况LZ4的哈希表使用的哈希方程还是最快速的xxhash。 当然,这样的设计也有弊端。哈希表越小,其key也会越少。这就表示会有更多的哈希冲突发生,这是不可避免的。而更多的哈希冲突则代表了更少的匹配项。 并且哈希表越小也代表了滑动窗口也会更小,也就是说,更多的匹配项会由于距离太远而被舍弃。更少的匹配项就会代表较小的压缩比例,这就是为什么LZ4的压缩比例更不突出的原因。 展望 LZ4的应用场景非常广泛。 如《硅谷》中middle out被应用于VR中一样,LZ4由于压缩速度非常快,LZ4可以以非常小的延迟为代价带来更少的IO数量,以此来增加对带宽的利用。下一个项目就打算编一个 minimum IO protocol。 还有一点点猜想,如果出了1级缓存更大的cpu,那LZ4是不是能在不损害速度的情况下提升压缩比例呢?
备注:原文地址