
ALSS是半监督语义分割领域最早的文章之一,文章的动机仍然是ease the heavy human efforts of labeling pixel-level annotations。与弱监督领域通常采用的分类级标签数据和分类级损失函数不同,半监督学习更强调少量有标签数据与大量无标签数据的结合,其核心在于如何通过有标签数据更好地挖掘无标签数据的监督信息,从而达到提升模型性能而降低人力支出的目的。
ALSS提出采用对抗学习的方法,通过借鉴对抗生成网络里面的generator和discriminator结构来实现semi-supervised learning。
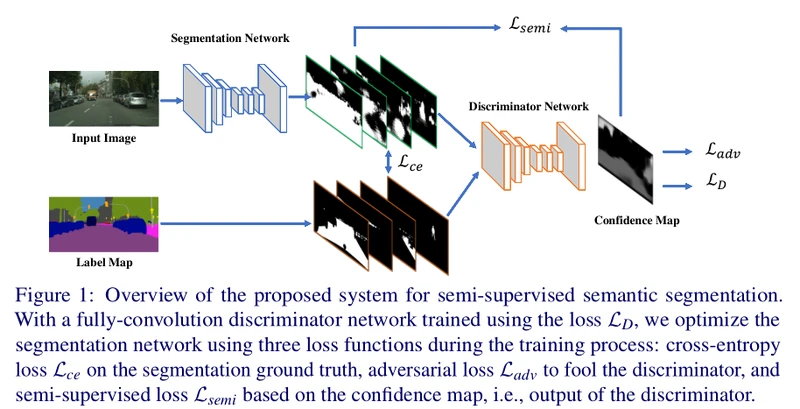
原文图1所示为ALSS的网络架构示意图。原文采用的分割网络Backbone是ResNet101-DeepLabv2,discriminator是一个5层的全卷积网络。Discriminator会将输入的prediction score maps转化为confidence map,具体地,当输入为ground-truth label时,我们期望得到一张全1的confidence map,而当输入为prediction score maps时,我们期望得到一张全0的confidence map,这样我们就可以认为prediction输出的confidence map中confidence值较大的像素区域和ground-truth label的分布比较接近。作者把segmentation network看做GAN中的generator,并为segmentation network设计了adversarial loss,即尽量使得predictions的confidence map与ground-truth的接近。总的来说,整个网络会同时受到labeled data和unlabeled data的监督,segmentation network和discriminator是同时进行对抗式训练的,类似于GAN中的generator和discriminator。Segmentation network输入labeled data时,会受到cross entropy loss和adversarial loss的监督,而在输入unlabeled data时,会受到masked cross entropy loss和adversarial loss的监督,从而实现semi-supervised learning setting。具体地讲,由于unlabeled data无法直接利用label计算cross entropy loss,ALSS利用了discriminator的判别能力,通过把unlabeled data的predictions输入discriminator得到confidence map,再选取confidence大于某个阈值的区域生成相应的伪label,再计算cross entropy loss,这样相当于在直接生成的伪label上加了一层mask。

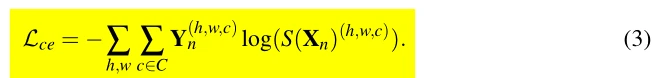
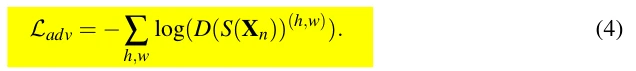

如原文式(2)-(5)所示,分割网络共受到三种损失的监督。从文章的描述以及模型源代码的实现细节得知,ALSS在训练一个iteration时实际上会从三个DataLoader中加载batch,一个batch作为segmentation network的labeled data input,一个batch作为segmentation network的unlabeled data input,另一个batch作为discriminator的labeled input,也就是说每个iteration内会对labeled Dataset做两次独立随机的batch采样,具体通过两个定义在同个dataset上的DataLoader实现。对于分割网络而言,对labeled data batch计算cross entropy loss和adversarial loss,对unlabeled data batch计算masked cross entropy loss和adversarial loss。比较重要的细节是,adversarial loss weight不能过大,通常在0.1以下,而且需要确保labeled data的weight比unlabeled data的weight大,因为unlabeled data没有收到cross entropy loss的较强监督,容易被adversarial loss过分地correct到ground-truth distribution而造成失真。
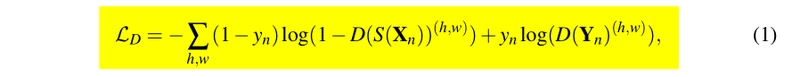
原文式(1)所示为discriminator的损失函数,对prediction输出的confidence map计算与all-zero map的交叉熵损失,对ground-truth输出的confidence map计算与all-one map的交叉熵损失。这里的训练细节在于,仅利用有标签的两个batch去计算损失,输入到segmentation network的unlabeled data predictions不用于训练discriminator;此外,整个网络需要先利用有标签的数据进行一定次数的full-supervised learning后再启用semi-supervised learning setting,以避免一开始就被unlabeled data产生的noisy mask和noisy prediction所影响。
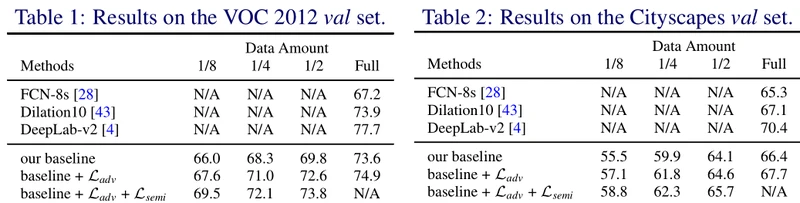
如原文表1、表2所示,ALSS网络在VOC 2012和CityScapes数据集上进行了性能测试,在仅仅利用原数据集一部分labeled data的情况下,unlabeled data的加入使得性能提高了3~4个百分点,证明文中所提出的adversarial semi-supervised learning setting是有效的。