
概述
算法流程法流程图如下:

首先对图像进行预处理,将图像大小变为550×550,送入主干网络进行卷积处理。主干网络采用的是ResNet101的Conv1_x——Conv5_x,分别对应YOLACT++的C1-C5。需要注意的是,YOLACT++算法将C3-C5的33卷积改为了33的可变形卷积,用来提升主干网络对不同形状实例的特征采样能力。
处理后的图像送入FPN中。P7——P3构成FPN网络。首先对C5进行卷积,得到P5;对P5进行双线性插值,使之扩大一倍,再与C4卷积后的图片叠加,得到P4,P3获得方法一致。P6则是对P5进行卷积和下采样,再对P6进行卷积和下采样得到P7,构成FPN网络。采用FPN的好处就是模型学习到特征更丰富,更有利于分割不同大小的目标物体
接下来两步是并行操作,经FPN处理后的数据分别送入预测网络和原型网络中,分别生成anchor和mask。在预测网络(prediction Head)中,P3-P7产生的五个特征图处理后得到三个输出,分别为类别置信度、位置偏移和mask置信度。接着通过Fast NMS算法,对每个目标选出最优的rol。
而在原型网络中,我们会使用FCN对P3产生的特征图进行卷积,最终得到各个类别的mask。
紧接着我们将预测网络的结果与原型网络的结果相乘。由于不同目标具有不同的类别置信度和mask置信度,因此这一步实际上就是根据预测网络输出结果,来对原型网络输出的各项类别的mask进行相加或者相减。如图,对于person类,由于预测网络输出结果为(+1,+1,+1,-1),故我们将原型网络输出的前三张图片相加后减去最后一张图片,即可获得这个目标的预测结果。
最后我们对获得的图片进行裁剪,将边界外的mask全部清零,再进行二值化。以0.5为阈值,将大于0.5的mask置一,小于0.5的mask置零,即获得最终的输出结果。
DCN可变形卷积
在主干网络中,YOLACT++算法将C3-C5的33卷积改为了33的可变形卷积,用来提升主干网络对不同形状实例的特征采样能力。现将DCN网络(可变形网络)介绍如下:
在计算机视觉领域,同一物体在不同场景,角度中未知的几何变换是检测/识别的一大挑战,通常来说我们有两种做法:
(1)通过充足的数据增强,扩充足够多的样本去增强模型适应尺度变换的能力。
(2)设置一些针对几何变换不变的特征或者算法,比如SIFT和sliding windows。
两种方法都有缺陷,第一种方法因为样本的局限性显然模型的泛化能力比较低,无法泛化到一般场景中,第二种方法则因为手工设计的不变特征和算法对于过于复杂的变换是很难的而无法设计。为了解决这个问题,我们常常使用可变形卷积来替代传统卷积,从而实现旋转不变性。
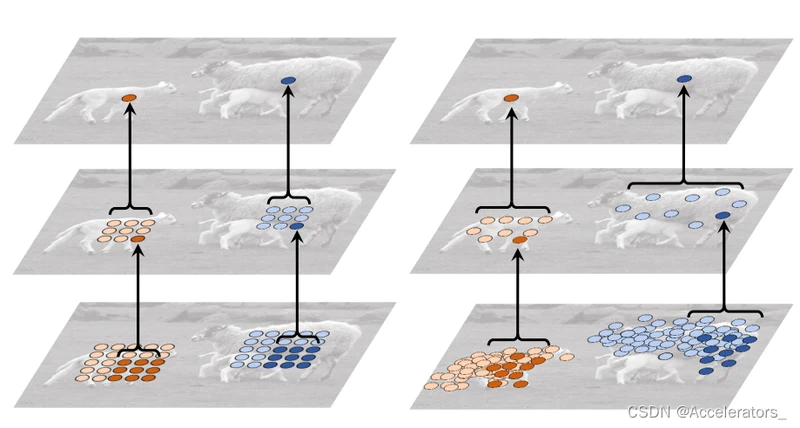
如图,在对羊进行卷积操作时,由于传统的卷积核为矩形,因此在提取羊的数据时,羊周围的环境数据不可避免地会被采样进去,对数据分析产生干扰。而使用可变形卷积时,卷积核的采样点不再是矩形,而是增加了偏移量,因此能够自适应羊的形状,尽量少地采集周围环境数据,从而减少干扰。
可变形卷积结构如下:
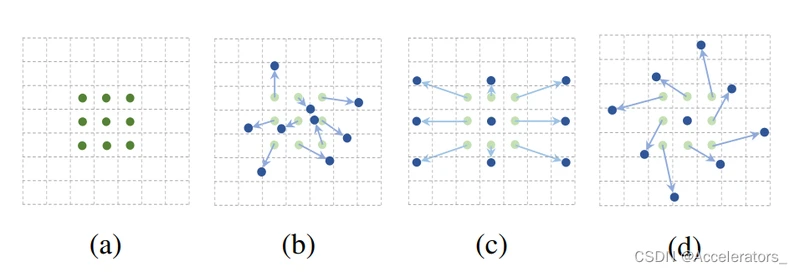
传统卷积结构如图(a)所示,卷积网络采样点固定,只能提取矩形框内数据。可变形卷积则在传统卷积采样点上增加了偏移量,如图(b)©(d),在正常的采样坐标上加上一个位移量(蓝色箭头),其中 ©(d) 作为 (b) 的特殊情况,展示了可变形卷积可以作为尺度变换,比例变换和旋转变换等特殊情况。

- 替换最后10个ResNet blocks
- 替换最后13个ResNet blocks
- 替换最后3个ResNet stage,block的间隔为3(每3个block替换1个)
- 替换最后3个ResNet stage,block的间隔为4(每4个block替换1个)
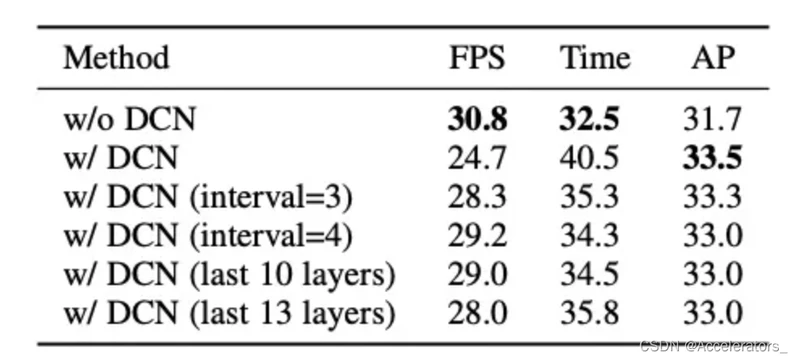
DCN (interval=3)的效果最好,耗时增加2.8ms,mAP提升1.6。
Prediction Head预测网络
FPN网络处理后的数据被分别送入原型网络和预测网络中,其中预测网络用以生成类别置信、位置偏移与mask coefficient,其与RetinaNet的结构对比如下:

输入的特征图先生成 anchor。每个像素点生成 3 个 anchor,比例是 1:1、1:2 和 2:1。五个特征图的 anchor 基本边长分别是 24、48、96、192 和 384。基本边长根据不同比例进行调整,确保 anchor 的面积相等。
为了便于理解,接下来以 P3 为例,标记它的维度为 W3H3256,那么它的 anchor 数就是 a3 = W3H33。接下来 Prediction Head 为其生成三类输出:
- 类别置信。因为 COCO 中共有 81 类(包括背景),所以其维度为 a3*81;
- 位置偏移,维度为 a3*4;
- mask coefficient,维度为 a3*32。
对 P4-P7 进行的操作是相同的,最后将这些结果拼接起来,标记 a = a3 + a4 + a5 + a6 + a7,得到: - 全部类别置信。因为 COCO 中共有 81 类(包括背景),所以其维度为 a*81;
- 全部位置偏移,维度为 a*4;
- 全部 mask coefficient,维度为 a*32。
Fast NMS
在预测网络处理后,往往会生成大量冗余的anchor干扰判断,此时往往使用NMS算法来消除多余的anchor,为每一个目标保留最合适的候选框。

- 定义置信度阈值和IOU阈值取值。
- 按置信度降序排列边界框bounding_box
- 从bbox_list中删除置信度小于阈值的预测框
- 循环遍历剩余框,首先挑选置信度最高的框作为候选框.
- 接着计算其他和候选框属于同一类的所有预测框和当前候选框的IOU。
- 如果上述任两个框的IOU的值大于IOU阈值,那么从box_list中移除置信度较低的预测框
- 重复此操作,直到遍历完列表中的所有预测框。
而YOLACT++算法采用的是Fast NMS算法,其流程如下:

- 如图,假设对于某一类别共有5个预测框,首先将其根据置信度降序排列,命名为b1—b5,两两之间计算IOU,填入矩阵中。
- 由于IOU计算的对称性,矩阵必然关于主对角线对称,而主对角线值必然为1,因此直接舍去主对角线与下三角
- 在处理过后,每一列的数据均为该预测框与其他置信度更高的预测框之间的IOU,因此直接每列选出IOU最大值代表该列,进行下一步计算
- 将每列的最大值逐一与IOU阈值比较,若超过阈值,表明该列与另一个置信度高于该列的预测框重合过高,可以直接抑制该列,保留其余IOU小于阈值的预测框。
值得注意的是,在存在N个预测框的情况下,传统NMS算法最多需要执行 N ( N − 1 ) 2 \frac{N(N-1)}{2} 2N(N−1)次运算,而Fast NMS需要执行 N 2 N^2 N2次运算,其计算量远大于传统NMS算法。但由于NMS算法流程是串行运算,每次抑制都需要选出当前置信度最高的候选框,抑制IOU超过阈值的预测框,再重复该操作。但Fast NMS是并行计算,无论各个预测框置信度为多少,都只需两两之间计算IOU即可,可以直接调用GPU进行运算,显著降低了运算时间。
此外,NMS算法处理的是同一类别的所有预测框数据,而这些预测框所预测的目标并不一定为同一个目标,而对于目标检测任务,目标的数量是无法事先确定的,故需要使用NMS算法抑制多余预测框,而无法直接保留置信度最大的预测框。
参考博客
https://zhuanlan.zhihu.com/p/
https://blog.csdn.net/kevin_zhao_zl/article/details/
https://zhuanlan.zhihu.com/p/
https://zhuanlan.zhihu.com/p/