
作者:霞落满天
第一部分 是我以前公司的一则正式案例:
第二部分 是我另一个博客上写的主要是最近发现大家问的比较多就写了此文
第一部分 线上真实故障案例
下面是一个老系统,代码写的有点问题导致出现这样一个JVM占比过高的问题,正常情况下也就是CPU负载不高的时候21:00左右的,也有30万,但是再多一点30几万就是阈值,就会出现堆积。
这个队列一直是增长的快。

这个是zabbix的CPU监控图,可以看出某些时段CPU会有性能毛刺:

经过跟同事一起讨论发现是系统框架中 kafka producer 使用了线程池,但设置较小,而消息量比较大,导致消息堆积

我建议在项目中,将线程数量加大。
下面是分析过程:
1、 从dump文件来看kafka.producer.KafKaProducerImpl这个对象中的queue占用了大量内存,这个类应该fx-kafka中提供的功能,用来写业务kafka的;
从图来看,堆内存已经占用了1.4G,可能存在内存泄露风险。

2、 建议查看一下dump文件中的线程消耗CPU情况,
a、可能是有线程在不停的循环造成的CPU过高;
b、 gc线程不停回收造成?
线上问题当时的CPU占用情况如图所示:

下面是当时java内存dump





=========================
第二部分 JVM常见排障步骤
0.jps
这个输出java进程pid
#jps
查看java的线程
#top -Hp 25448
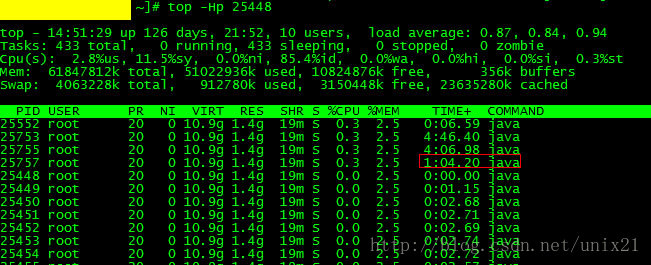
如图25757这个线程比较耗时,看看他在做什么

注意需要折算出线程pid的16进制值,然后jstack。
可以打印更多信息
#jstack pid | grep -A 20 649d

参考:JVM调优之jstack找出最耗cpu的线程并定位代码
1.jstack
#jstack -l pid > jstack.log
使用jstack命令输出这一时刻的线程栈
2.jmap
#jmap -dump:format=b,file=heapDump 6900
#jmap -dump:live,format=b,file=dump.bin 6900
-dump:[live,]format=b,file=<filename> 使用hprof二进制形式,输出jvm的heap内容到文件=.
live子选项是可选的,假如指定live选项,那么只输出活的对象到文件.
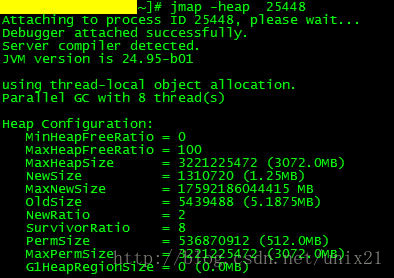
jmap查看堆内存大小
#jmap -heap pid
注意:jmap使用的时候jvm是处在停顿状态的,只能在服务不可用的时候为了解决问题来使用,否则会造成服务中断。
使用jmap -histo[:live] pid查看堆内存中的对象数目、大小统计直方图,如果带上live则只统计活对象,如下:
# jmap -histo:live pid | more
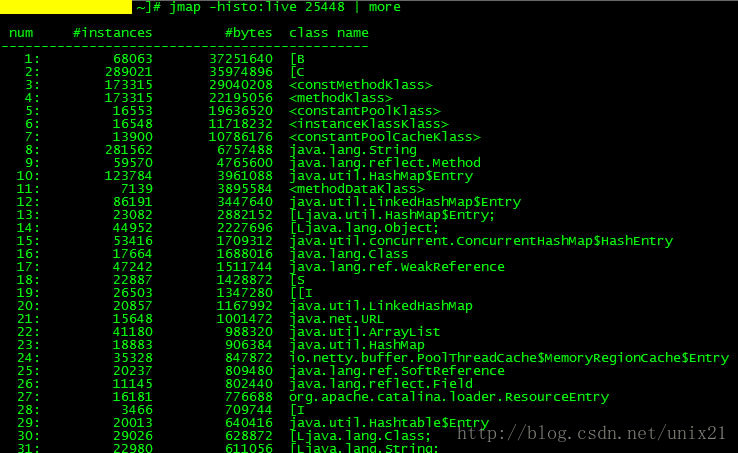
需要使用MAT工具分析jmap dump的内存
3.jstat
jstat -gcutil pid
250毫秒一次采样4次

可以看出:
堆内存 = 年轻代 + 年老代 + 永久代
年轻代 = Eden区 + 两个Survivor区(From和To)
现在来解释各列含义:
S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
E、hprof(Heap/CPU Profiling Tool)
4.gcore
#gdb -q --pid=1990
(gdb) generate-core-file
(gdb) detach
(gdb) quit
jmap -dump:format=b,file=heap.hprof /usr/lib/jvm/jre-1.7.0-openjdk.x86_64/bin/java core.1990
需要具体jdk对应的bin/java
参考:
gcore 获取程序core dump file 但程序不用退出,gdb 分析core
java程序性能分析之thread dump和heap dump
5.堆外内存泄露分析
top出来java占用内存极大而jmap出来的很小,说明有堆外内存泄露。
综合使用参考: JVM性能调优监控工具jps、jstack、jmap、jhat、jstat、hprof使用详解
JVM性能调优监控工具专题一:JVM自带性能调优工具(jps,jstack,jmap,jhat,jstat,hprof)
JVM性能调优监控工具专题二:VisualVM基本篇之监控JVM内存,CPU,线程
下面一些写的好,如果觉得前面不够尽兴可以延申阅读
jvm系列六、windows用jdk自带工具jps、jstack找出性能最差的代码 【windows下的比较实用】
面试官问:平时碰到系统CPU飙高和频繁GC,你会怎么排查【评判标准】
1.如果是Full GC次数过多,那么通过jstack得到的线程信息会是类似于VM Thread之类的线程;
2.而如果是代码中有比较耗时的计算,那么我们得到的就是一个线程的具体堆栈信息。
3.如果说该接口中有某个位置是比较耗时的,由于我们的访问的频率非常高,那么大多数的线程最终都将阻塞于该阻塞点,这样通过多个线程具有相同的堆栈日志,我们基本上就可以定位到该接口中比较耗时的代码的位置。
4.waiting on condition
如果该线程本身就应该处于等待状态,比如用户创建的线程池中处于空闲状态的线程,那么这种线程的堆栈信息中是不会包含用户自定义的类的。这些都可以排除掉,而剩下的线程基本上就可以确认是我们要找的有问题的线程。通过其堆栈信息,我们就可以得出具体是在哪个位置的代码导致该线程处于等待状态了。
5.deadlock死锁这种情况基本上很容易发现
=========================
JVM很多时间是因为系统架构不合理导致的,比如过大的内存,其实系统只要稍微调整下,完全可以提前避免。推荐看看我精心制作的课程《高性能微服务架构设计模式》你会对系统架构有很大的提高。
高性能微服务架构设计模式
主讲:霞落满天
现在企业开发都是微服务架构,但是有很多问题,比如分布式定义,分布式的微服务怎么拆分,什么时候拆分,怎么做到高性能,针对这些问题我录制了一期学习视频。有任何学习问题可以给我留言
视频地址有试听:https://edu.csdn.net/course/detail/27256/
课程大纲
开篇 高性能系统架构的分布式理论基础
模型 可无限扩展的AKF立方
问题 亿级QPS的电商网站遇到的问题
模式 CQRS模式进行架构设计
模式 事件溯源模式进行架构设计
结尾 新问题
课程精彩图片分享:
